Bei Verwendung einer Indexierungstechnologie ist zu beachten, dass ein Index zuerst erstellt werden muss, damit er durchsucht werden kann. Da ein Großteil der schwierigen Sucharbeit eigentlich im Voraus bei der Indexerstellung erledigt wird, laufen Suchabfragen zur Laufzeit schnell ab. Dennoch lohnt es sich, darauf hinzuweisen, dass der Indexierungsprozess selbst eine gewisse Zeit in Anspruch nehmen kann. Diese Zeit nimmt proportional zu dem zu indexierenden Datenvolumen zu.
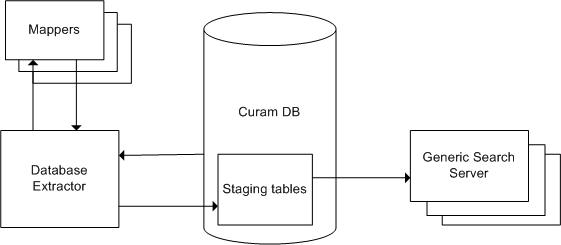
Die Initialisierung des Servers für generische Suche erfolgt in zwei Phasen.
In der ersten Phase werden die vorhandenen Anwendungsdaten aus der Anwendung in eine Gruppe von Datenbanktabellen exportiert, die vom Server für generische Suche verwendet werden, die Staging-Tabellen. Dieser Exportvorgang wurde als Batchprozess mit der Bezeichnung 'Extraktor der Datenbanksuche' implementiert und wird im Rahmen des Vertriebs des generische Servers für generische Suche bereitgestellt. Der Export braucht nur ein einziges Mal zu erfolgen, nämlich bei der Erstverwendung des Servers für generische Suche. Für jeden Suchservice werden spezielle Helper-Klassen benötigt, die so genannten Zuordnungsfunktionen. Sie unterstützen den Extraktor bei der Vorbereitung der Daten, die in die Staging-Tabellen importiert werden sollen.
In der zweiten Phase wird für jeden definierten Suchservice ein Index erstellt. Beim Start des Servers für generische Suche wird ein Prozess ausgeführt, um die entsprechenden Daten aus den Staging-Datenbanktabellen zu lesen und die Indizes sowie andere Datenstrukturen zu erstellen, die für Suchabfragen verwendet werden sollen. Sobald die Indizes erstellt sind, hat der Server die Möglichkeit, auf Suchanforderungen zu antworten. Informationen zur Leistungsoptimierung finden Sie in Leistung.