Una consecuencia del uso de una tecnología de indexación es que, para poder buscar en un índice, en primer lugar se debe crear. Puesto que una gran cantidad del trabajo de búsqueda se realiza esencialmente por adelantado en la construcción del índice, las búsquedas en tiempo de ejecución resultan más rápidas; no obstante, cabe tener en cuenta que el propio proceso de indexación puede tardar algún tiempo, y este tiempo aumenta proporcionalmente con la cantidad de datos que se deben indexar.
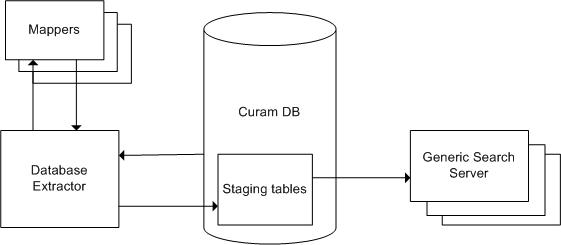
La inicialización del Servidor de búsqueda genérico se realiza en dos fases.
En la primera fase, los datos de la aplicación existentes se exportan de la aplicación a un conjunto de tablas de base de datos utilizado por el Servidor de búsqueda genérico: las tablas base. Esta exportación se ha implementado como un proceso por lotes, que se conoce como el extractor de búsqueda de base de datos, y se proporciona como parte de la distribución del Servidor de búsqueda genérico. Solo es necesario realizar la exportación una vez, cuando el Servidor de búsqueda genérico se utiliza por primera vez. Se necesitan clases auxiliares especiales denominadas correlacionadores para cada servicio de búsqueda; estas ayudan al extractor a preparar los datos que deben importarse en las tablas base.
En la segunda fase, se construye un índice para cada servicio de búsqueda definido. Cuando se inicia el servidor de búsqueda genérico, se ejecuta un proceso para leer los datos adecuados de las tablas de la base de datos de transferencia y construir los índices y otras estructuras de datos que se utilizarán para realizar búsquedas. Una vez construidos los índices, el servidor estará en condiciones de responder a las solicitudes de búsqueda. Encontrará información sobre cómo optimizar este rendimiento en el apartado Rendimiento